收集箱
去掉第一行:tail -n +2 file
文件/目录操作
获取文件名和扩展名
1
2
3
| filename=$(basename "$fullfile")
extension="${filename##*.}"
filename="${filename%.*}"
|
遍历目录下的文件
1
2
3
4
| for entry in "$search_dir"/*
do
echo "$entry"
done
|
表格数据处理
最经典的成绩表:
1
2
3
| 张三 100 90 80
李四 90 100 90
王五 80 80 100
|
数据有4列,分别表示姓名,语文,数学,英语成绩,给出语文,数学,英语分数最高的人名。
按列排序,第一个想到的就是sort了,方案:
# 输出语文成绩最高的一行
sort -nk2,2 input
# 输出数学成绩最高的一行
sort -nk3,3 input
# 输出英语成绩最高的一行
sort -nk4,4 input
使用sort对某一列排序,就可以得出单科排序后的结果。如果只要最高的,head -n 1就可以了。如果一定要只输出人名,再awk '{print $1'}。
sort -nk3,3 的使用可以参考Linux命令学习笔记 | 木杉的博客
表格数据处理2
依然是成绩表,但是格式会麻烦一些:
1
2
3
4
5
6
7
8
9
| 张三 语文 100
张三 数学 90
张三 英语 80
李四 语文 90
李四 数学 80
李四 英语 100
王五 语文 80
王五 数学 100
王五 英语 90
|
需要按照总分排序。
这里涉及到了加法逻辑。感觉需要awk出马了。有两个处理逻辑,一个是完全用awk处理,一种是用awk处理为sort方便处理的中间格式,然后用管道。
方案1:完全使用awk
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| #!/bin/awk
{
a[$1]+=$3;
}
END{
for(key in a){
b[a[key]]=key;
}
n=asorti(b,sortKey);
for(i=1;i<=n;i++){
print b[sortKey[i]]" "sortKey[i];
}
}
|
awk中内置了两个排序函数asort和asorti。asort对值排序,asorti对索引排序。
需要注意的是,asort会破坏原数组的索引。这是因为awk中都是关联数组,数组的顺序由key控制。所以想要按照一定的顺序排序值,必须从新设置顺序的索引。
方案2:结合sort
awk '{a[$1]+=$3}END{for(i in a){print i,a[i]}}' input3 | sort -k2n
只使用awk来计算总分,然后输出为人名和总分两列,然后就可以很方便地用sort排序了。个人倾向用这种方法,符合UNIX风格。
使用AWK处理二维数据(日志数据)
先用grep处理后的数据格式为:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| "CheckOrderAntispam":0.022068977355957
"CheckOrderAntispam":0.025101900100708
"CheckOrderAntispam":0.025767087936401
"CheckOrderAntispam":0.02592396736145
"CheckOrderAntispam":0.119145154953
"buildData":0.00030207633972168
"buildData":4.7922134399414
"buildData":5.9127807617188
"buildData":6.3896179199219
"checkBalancePay":1.1920928955078
"checkBalancePay":1.9073486328125
"checkBalancePay":9.5367431640625
"checkBalancePay":9.5367431640625
"checkBalancePay":9.5367431640625
"checkCanUseCOD":1.0013580322266
|
是典型的key:value格式。需求是统计出来最大值,最小值,平均值,大于0.5的值。我自然而然的想到了awk的数组,不过awk的数组比较原始,需要花些时间学习,大家可以参考这篇文章:
linux awk数组操作详细介绍 - 程默 - 博客园
然后编写代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| {
total[$1]+=$2;
count[$1]+=1;
if(!($1 in max) || $2 > max[$1]){
max[$1]=$2;
}
if(!($1 in min) || $2 < min[$1]){
min[$1]=$2;
}
if($2>0.5){
bigcount[$1]+=1;
big[$1,bigcount[$1]]=$2;
}
}
END{
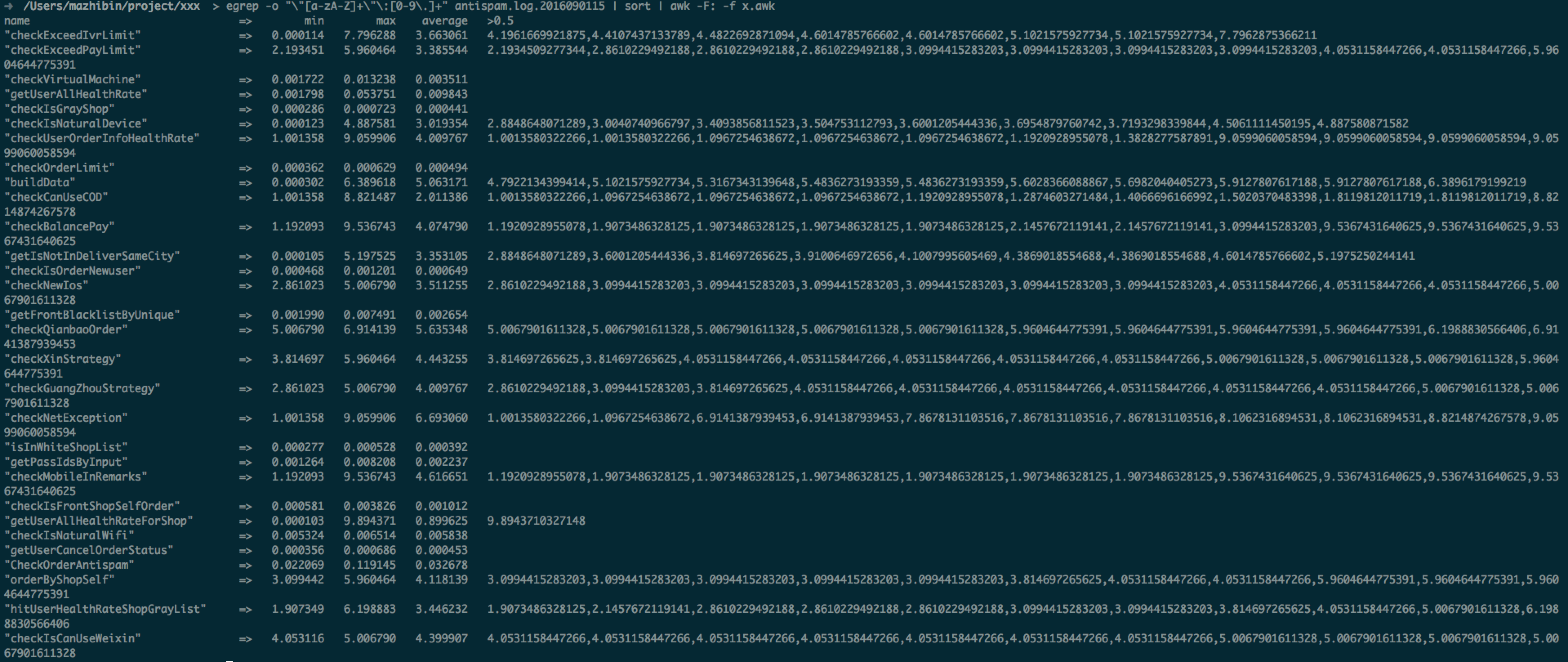
printf("%-35s => %10s %10s %10s %s\n","name","min","max","average",">0.5");
for(i in total){
average=total[i]/count[i];
bigstr="";
for(j=1;j<=bigcount[i];j++){
if(bigstr!=""){
bigstr=bigstr","big[i,j];
}else{
bigstr=big[i,j];
}
}
printf("%-35s => %10f %10f %10f %s\n",i,min[i],max[i],average,bigstr);
}
}
|
输出为:
其中格式化输出的部分可以参考:
awk之printf详解-zooyo-ChinaUnix博客
错误
错误:
致命错误: 试图在标量环境中使用数组“a”
不使用$就可以了

