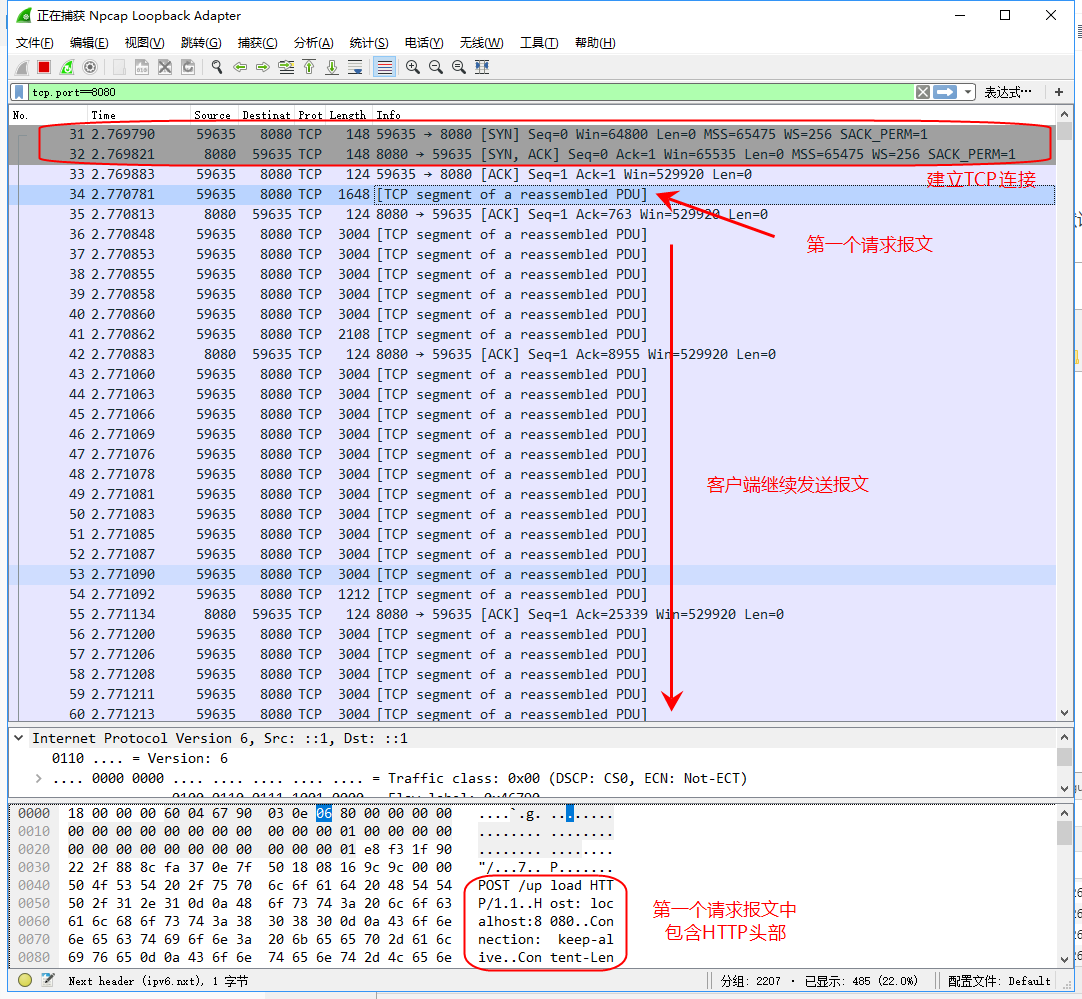
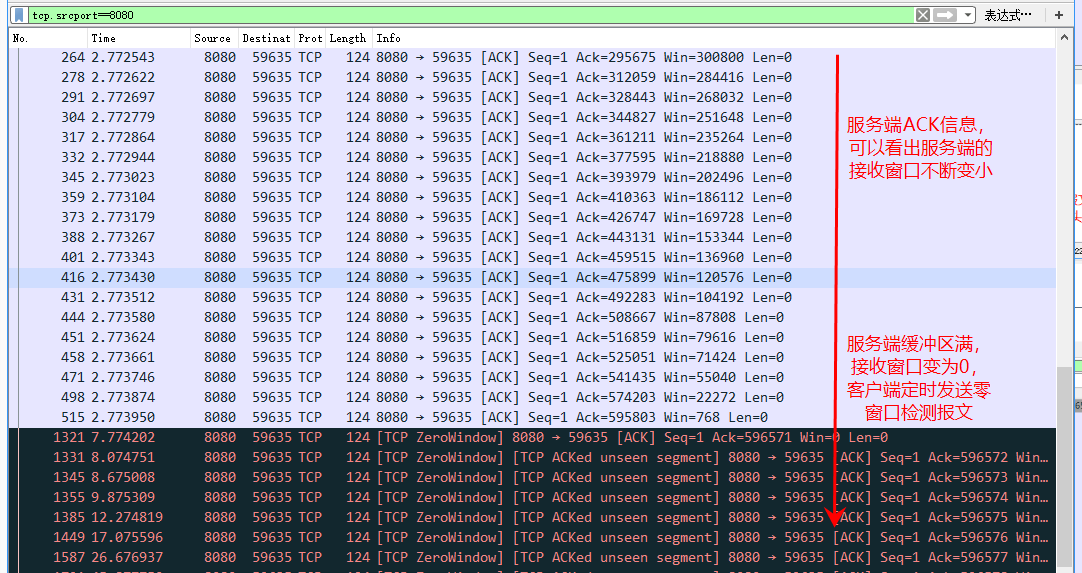
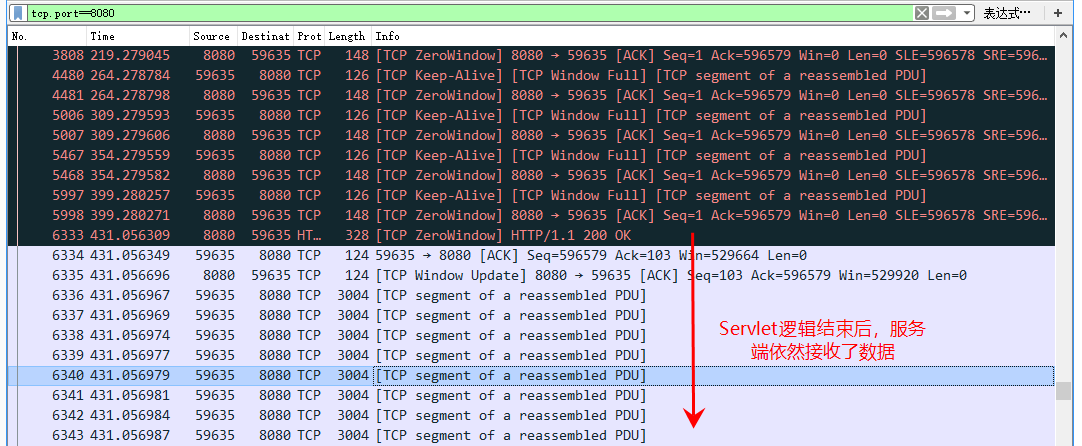
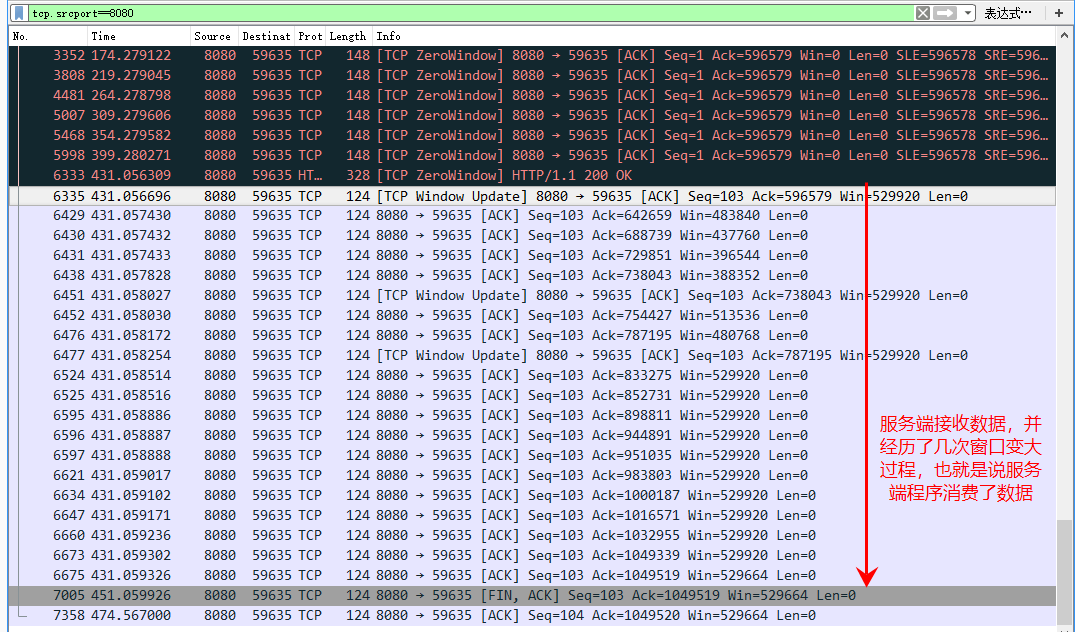
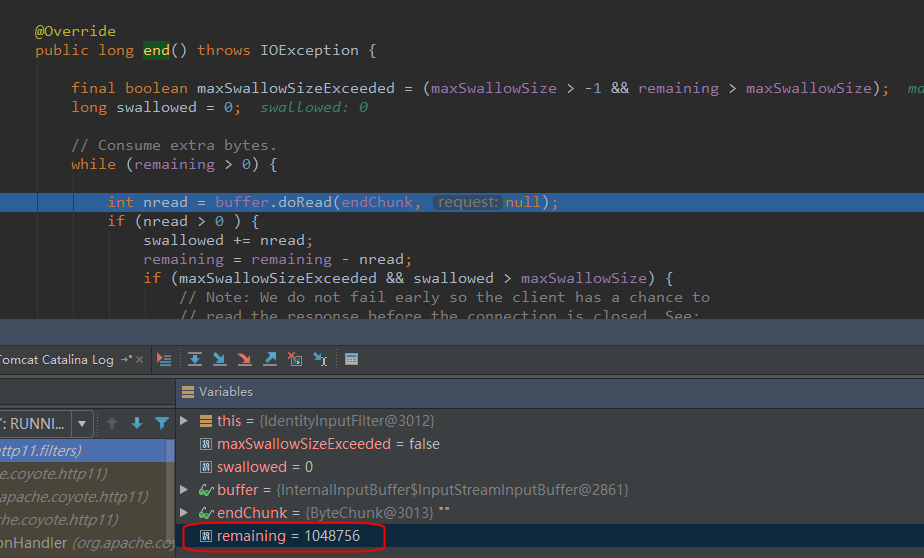
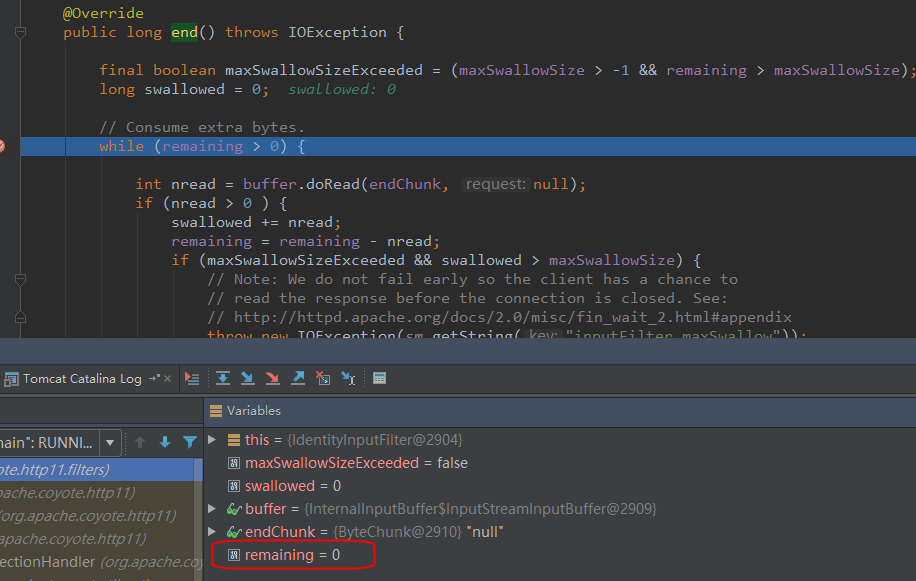
// 如果请求体剩余的没有读取的大小大于零,则Tomcat吃掉它 while (remaining > 0) {
int nread = buffer.doRead(endChunk, null); if (nread > 0 ) { swallowed += nread; remaining = remaining - nread;
// 如果读取了太多了字节,则抛出异常 if (maxSwallowSizeExceeded && swallowed > maxSwallowSize) { // Note: We do not fail early so the client has a chance to // read the response before the connection is closed. See: // http://httpd.apache.org/docs/2.0/misc/fin_wait_2.html#appendix thrownew IOException(sm.getString("inputFilter.maxSwallow")); } } else { // errors are handled higher up. remaining = 0; } }
// If too many bytes were read, return the amount. return -remaining; }
// Note: We do not fail early so the client has a chance to // read the response before the connection is closed. See: // http://httpd.apache.org/docs/2.0/misc/fin_wait_2.html#appendix
Below is a message from Roy Fielding, one of the authors of HTTP/1.1.
Why the lingering close functionality is necessary with HTTP The need for a server to linger on a socket after a close is noted a couple times in the HTTP specs, but not explained. This explanation is based on discussions between myself, Henrik Frystyk, Robert S. Thau, Dave Raggett, and John C. Mallery in the hallways of MIT while I was at W3C.
If a server closes the input side of the connection while the client is sending data (or is planning to send data), then the server's TCP stack will signal an RST (reset) back to the client. Upon receipt of the RST, the client will flush its own incoming TCP buffer back to the un-ACKed packet indicated by the RST packet argument. If the server has sent a message, usually an error response, to the client just before the close, and the client receives the RST packet before its application code has read the error message from its incoming TCP buffer and before the server has received the ACK sent by the client upon receipt of that buffer, then the RST will flush the error message before the client application has a chance to see it. The result is that the client is left thinking that the connection failed for no apparent reason.
There are two conditions under which this is likely to occur:
sending POST or PUT data without proper authorization sending multiple requests before each response (pipelining) and one of the middle requests resulting in an error or other break-the-connection result. The solution in all cases is to send the response, close only the write half of the connection (what shutdown is supposed to do), and continue reading on the socket until it is either closed by the client (signifying it has finally read the response) or a timeout occurs. That is what the kernel is supposed to do if SO_LINGER is set. Unfortunately, SO_LINGER has no effect on some systems; on some other systems, it does not have its own timeout and thus the TCP memory segments just pile-up until the next reboot (planned or not).
Please note that simply removing the linger code will not solve the problem -- it only moves it to a different and much harder one to detect.